-
November 30, 201615 Years of ConcurrencyTweet
In a Tale of Three Safeties, we discussed three kinds of safety: type, memory, and concurrency. In this follow-on article, we will dive deeper into the last, and perhaps the most novel yet difficult, one. Concurrency-safety led me to the Midori project in the first place, having spent years on .NET and C++ concurrency models leading up to joining. We built some great things that I’m very proud of during this time. Perhaps more broadly interesting, however, are the reflections on this experience after a few years away from the project.
I’ve tried to write this article about 6 times since earlier this year, and I’m thrilled to finally share it. I hope that it’s useful to anyone interested in the field, and especially anybody who is actively innovating in this area. Although the code samples and lessons learned are deeply rooted in C#, .NET, and the Midori project, I have tried to generalize the ideas so they are easily consumable regardless of programming language. I hope you enjoy!
Background
For most of the 2000s, my job was figuring out how to get concurrency into the hands of developers, starting out as a relatively niche job on the CLR team at Microsoft.
Niche Beginnings
Back then, this largely entailed building better versions of the classic threading, locking, and synchronization primitives, along with attempts to solidify best practices. For example, we introduced a thread-pool to .NET 1.1, and used that experience to improve the scalability of the Windows kernel, its scheduler, and its own thread-pool. We had this crazy 128-processor NUMA machine that kept us busy with all sorts of esoteric performance challenges. We developed rules for how to do concurrency right – lock leveling, and so on – and experimented with static analysis. I even wrote a book about it.
Why concurrency in the first place?
In short, it was enormously challenging, technically-speaking, and therefore boatloads of fun.
I had always been a languages wonk. So, I was naturally fascinated by the decades of deep work in academia, including programming language and runtime symbiosis (especially Cilk and NESL), advanced type systems, and even specialized parallel hardware architectures (especially radical ones like the Connection Machine, and MIMD supercomputers, that innovated beyond our trustworthy pal, von Neumann).
Although some very large customers actually ran symmetric multiprocessor (SMP) servers – yes, we actually used to call them that – I wouldn’t say that concurrency was a very popular area to specialize in. And certainly any mention of those cool “researchy” sources would have gotten an odd glance from my peers and managers. Nevertheless, I kept at it.
Despite having fun, I wouldn’t say the work we did during this period was immensely impactful to the casual observer. We raised the abstractions a little bit – so that developers could schedule logical work items, think about higher levels of synchronization, and so on – but nothing game-changing. Nonetheless, this period was instrumental to laying the foundation, both technically and socially, for what was to come later on, although I didn’t know it at the time.
No More Free Lunch; Enter Multicore
Then something big happened.
In 2004, Intel and AMD approached us about Moore’s Law, notably its imminent demise. Power wall challenges would seriously curtail the ever-increasing year-over-year clock speed improvements that the industry had grown accustomed to.
Suddenly management cared a whole lot more about concurrency. Herb Sutter’s 2005 “Free Lunch is Over” article captured the fever pitch. If we couldn’t enable developers to write massively parallel software – something that was historically very difficult and unlikely to happen without significantly lower barriers to entry – both Microsoft and Intel’s businesses, and mutually beneficial business models, were in trouble. If the hardware didn’t get faster in the usual ways, software couldn’t automatically get better, and people would have less reason to buy new hardware and software. An end to the Wintel era and Andy and Bill’s Law, “What Andy giveth, Bill taketh away”.
Or, so the thinking went.
This is when the term “multicore” broke into the mainstream, and we began envisioning a world with 1,024 core processors and even more forward-looking “manycore” architectures that took a page from DSPs, mixing general purpose cores with specialized ones that could offload heavy-duty functions like encryption, compression, and the like.
As an aside, with 10 years of hindsight, things didn’t unfold exactly as we thought they would. We don’t run PCs with 1,024 traditional cores, although our GPUs have blown way past that number, and we do see more heterogeneity than ever before, especially in the data center where FPGAs are now offloading critical tasks like encryption and compression.
The real big miss, in my opinion, was mobile. This was precisely when the thinking around power curves, density, and heterogeneity should have told us that mobile was imminent, and in a big way. Instead of looking to beefier PCs, we should have been looking to PCs in our pockets. Instead, the natural instinct was to cling to the past and “save” the PC business. This is a classical innovator’s dilemma although it sure didn’t seem like one at the time. And of course PCs didn’t die overnight, so the innovation here was not wasted, it just feels imbalanced against the backdrop of history. Anyway, I digress.
Making Concurrency Easier
As a concurrency geek, this was the moment I was waiting for. Almost overnight, finding sponsors for all this innovative work I had been dreaming about got a lot easier, because it now had a real, and very urgent, business need.
In short, we needed to:
- Make it easier to write parallel code.
- Make it easier to avoid concurrency pitfalls.
- Make both of these things happen almost “by accident.”
We already had threads, thread-pools, locks, and basic events. Where to go from here?
Three specific projects were hatched around this point and got an infusion of interest and staffing.
Software Transactional Memory
Ironically, we began with safety first. This foreshadows the later story, because in general, safety took a serious backseat until I was able to pick it back up in the context of Midori.
Developers already had several mechanisms for introducing concurrency, and yet struggled to write correct code. So we sought out those higher level abstractions that could enable correctness as if by accident.
Enter software transactional memory (STM). An outpouring of promising research had been coming out in the years since Herlihy and Moss’s seminal 1993 paper and, although it wasn’t a panacea, a number of us became enamored with its ability to raise the abstraction level.
STM let you write things like this, and get automatic safety:
void Transfer(Account from, Account to, int amt) { atomic { from.Withdraw(amt); to.Deposit(amt); } }Look ma, no locks!
STM could handle all of the decisions transparently like figuring out how coarse- or fine-grained synchronization to use, the contention policies around that synchronization, deadlock detection and prevention, and guarantee that you didn’t forget to lock when accessing a shared data structure. All behind a tantalizingly simple keyword,
atomic.STM also came with simple, more declarative, coordination mechanisms, like orElse. So, although the focus was on eliminating the need to manually manage locking, it also helped evolve synchronization between threads.
Unfortunately, after a few years of prototyping deep runtime, OS, and even hardware support, we abandoned the efforts. My brief summary is that it’s more important to encourage good concurrency architecture than it is to make poor ones “just work”, although I have written more details here and here. It was this higher level architecture that we should focus on solving first and foremost and, after the dust settled, see what gaps remained. It wasn’t even clear that STM would be the correct tool for the job once we got to that point. (In hindsight, I do think it’s one of the very many reasonable tools in the toolbelt, although with more distributed application architectures on the rise, it’s a dangerous thing to give to people.)
Our STM efforts weren’t a complete failure, however. It was during this time that I began experimenting with type systems for safe concurrency. Moreover, bits and pieces ended up incorporated into Intel’s Haswell processor as the Transactional Synchronization Extensions (TSX) suite of instructions, delivering the capability to leverage speculative lock elision for ultra-cheap synchronization and locking operations. And again, I worked with some amazing people during this time.
Parallel Language Integrated Query (PLINQ)
Alongside STM, I’d been prototyping a “skunkworks” data parallel framework, on nights and weekends, to leverage our recent work in Language Integrated Query (LINQ).
The idea behind parallel LINQ (PLINQ) was to steal a page from three well-researched areas:
-
Parallel databases, which already parallelized SQL queries on users’ behalves without them needing to know about it, often with impressive results.
-
Declarative and functional languages, which often used list comprehensions to express higher-level language operations that could be aggressively optimized, including parallelism. For this, I deepened my obsession with Haskell, and was inspired by APL.
-
Data parallelism, which had quite a lengthy history in academia and even some more mainstream incarnations, most notably OpenMP.
The idea was pretty straightforward. Take existing LINQ queries, which already featured operations like maps, filters, and aggregations – things that were classically parallelizable in both languages and databases – and auto-parallelize them. Well, it couldn’t be implicit, because of side-effects. But all it took was a little
AsParallelto enable:// Sequential: var q = (from x in xs where p(x) select f(x)).Sum(); // Parallel: var q = (from x in xs.AsParallel() where p(x) select f(x)).Sum();This demonstrates one of the great things about data parallelism. It can scale with the size of your inputs: either data quantity, expense of the operations against that data, or both. And when expressed in a sufficiently high-level language, like LINQ, a developer needn’t worry about scheduling, picking the right number of tasks, or synchronization.
This is essentially MapReduce, on a single machine, across many processors. Indeed, we later collaborated with MSR on a project called DryadLINQ which not only ran such queries across many processors, but also distributed them across many machines too. (Eventually we went even finer-grained with SIMD and GPGPU implementations.) This eventually led to Microsoft’s own internal equivalent to Google’s MapReduce, Cosmos, a system that powers a lot of big data innovation at Microsoft still to this date.
Developing PLINQ was a fond time in my career and a real turning point. I collaborated and built relationships with some amazing people. BillG wrote a full-page review of the idea, concluding with “We will have to put more resources specifically on this work.” Such strong words of encouragement didn’t hurt with securing funding to deliver on the idea. It also attracted the attention of some incredible people. For example, Jim Gray took notice, and I got to experience his notorious generosity 1st hand, just two months before his tragic disappearance.
Needless to say, this was an exciting time!
Interlude: Forming the PFX Team
Around this time, I decided to broaden the scope of our efforts beyond just data parallelism, tackling task parallelism and other concurrency abstractions. So I went around pitching the idea of forming a new team.
Much to my surprise, a new parallel computing group was being created in the Developer Division in response to the changing technology landscape, and they wanted to sponsor these projects. It was an opportunity to roll everything up under a nice top-level business theme, unify recruiting efforts, and take things even further, eventually branching out into C++, GPGPUs, and more.
So, obviously, I said yes.
I named the team “PFX”, initially short for “parallel frameworks”, although by the time we shipped marketing working its magic on us, renaming it to “Parallel Extensions to .NET.” This team’s initial deliverable encompassed PLINQ, task parallelism, and a new effort, Coordination Data Structures (CDS), meant to handle advanced synchronization efforts, like barrier-style synchronization, concurrent and lock-free collections derived from many great research papers, and more.
Task Parallel Library
This brings me to task parallelism.
As part of PLINQ, we needed to create our own concept of parallel “tasks.” And we needed a sophisticated scheduler that could scale automatically given the machine’s available resources. Most existing schedulers were thread-pool like, in that they required that a task run on a separate thread, even if doing so was not profitable. And the mapping of tasks to threads was fairly rudimentary, although we did make improvements to that over the years.
Given my love of Cilk, and the need to schedule lots of potentially-recursive fine-grained tasks, choosing a work stealing scheduler for our scheduling architecture was a no-brainer.
At first, our eyes were locked squarely on PLINQ, and so we didn’t pay as much attention to the abstractions. Then MSR began exploring what standalone a task parallel library would look like. This was a perfect partnership opportunity and so we started building something together. The
Task<T>abstraction was born, we rewrote PLINQ to use it, and created a suite ofParallelAPIs for common patterns such as fork/join and parallelforandforeachloops.Before shipping, we replaced the guts of the thread-pool with our new shiny work-stealing scheduler, delivering unified resource management within a process, so that multiple schedulers wouldn’t fight with one another. To this day, the code is almost identical to my early implementation in support of PLINQ (with many bug fixes and improvements, of course).
We really obsessed over the usability of a relatively small number of APIs for a long time. Although we made mistakes, I’m glad in hindsight that we did so. We had a hunch that
Task<T>was going to be core to everything we did in the parallelism space but none of us predicted the widespread usage for asynchronous programming that really popularized it years later. Now-a-days, this stuff powersasyncandawaitand I can’t imagine life withoutTask<T>.A Shout-Out: Inspiration From Java
I would be remiss if I didn’t mention Java, and the influence it had on my own thinking.
Leading up to this, our neighbors in the Java community had also begun to do some innovative work, led by Doug Lea, and inspired by many of the same academic sources. Doug’s 1999 book, Concurrent Programming in Java, helped to popularize these ideas in the mainstream and eventually led to the incorporation of JSR 166 into the JDK 5.0. Java’s memory model was also formalized as JSR 133 around this same time, a critical underpinning for the lock-free data structures that would be required to scale to large numbers of processors.
This was the first mainstream attempt I saw to raise the abstraction level beyond threads, locks, and events, to something more approachable: concurrent collections, fork/join, and more. It also brought the industry closer to some of the beautiful concurrent programming languages in academia. These efforts were a huge influence on us. I especially admired how academia and industry partnered closely to bring decades’ worth of knowledge to the table, and explicitly sought to emulate this approach in the years to come.
Needless to say, given the similarities between .NET and Java, and level of competition, we were inspired.
O Safety, Where Art Thou?
There was one big problem with all of this. It was all unsafe. We had been almost exclusively focused on mechanisms for introducing concurrency, but not any of the safeguards that would ensure that using them was safe.
This was for good reason: it’s hard. Damn hard. Especially across the many diverse kinds of concurrency available to developers. But thankfully, academia had decades of experience in this area also, although it was arguably even more “esoteric” to mainstream developers than the parallelism research. I began wallowing in it night and day.
The turning point for me was another BillG ThinkWeek paper I wrote, Taming Side Effects, in 2008. In it, I described a new type system that, little did I know at the time, would form the basis of my work for the next 5 years. It wasn’t quite right, and was too tied up in my experiences with STM, but it was a decent start.
Bill again concluded with a “We need to do this.” So I got to work!
Hello, Midori
But there was still a huge problem. I couldn’t possibly imagine doing this work incrementally in the context of the existing languages and runtimes. I wasn’t looking for a warm-and-cozy approximation of safety, but rather something where, if your program compiled, you could know it was free of data races. It needed to be bulletproof.
Well, actually, I tried. I prototyped a variant of the system using C# custom attributes and static analysis, but quickly concluded that the problems ran deep in the language and had to be integrated into the type system for any of the ideas to work. And for them to be even remotely usable. Although we had some fun incubation projects at the time (like Axum), given the scope of the vision, and for a mixture of cultural and technical reasons, I knew this work needed a new home.
So I joined Midori.
An Architecture, and An Idea
A number of concurrency gurus were also on the Midori team, and I had been talking to them about all of this for a couple years leading up to me joining. At a top-level, we knew the existing foundation was the wrong one to bet on. Shared-memory multithreading really isn’t the future, we thought, and notably absent from all of my prior work was fixing this problem. The Midori team was set up exactly to tackle grand challenges and make big bets.
So, we made some:
-
Isolation is paramount, and we will embrace it wherever possible.
-
Message passing will connect many such isolated parties through strongly typed RPC interfaces.
-
Namely, inside of a process, there exists a single message loop, and, by default, no extra parallelism.
-
A “promises-like” programming model will be first class so that:
- Synchronous blocking is disallowed.
- All asynchronous activity in the system is explicit.
- Sophisticated coordination patterns are possible without resorting to locks and events.
To reach these conclusions we were heavily inspired by Hoare CSPs, Gul Agha’s and Carl Hewitt’s work on Actors, E, π, Erlang, and our own collective experiences building concurrent, distributed, and various RPC-based systems over the years.
I didn’t say this before, however message passing was notably absent in my work on PFX. There were multiple reasons. First, there were many competing efforts, and none of them “felt” right. For instance, the Concurrency and Coordination Runtime (CCR) was very complex (but had many satisfied customers); the Axum language was, well, a new language; MSR’s Cω was powerful, but required language changes which some were hesitant to pursue (though the derivative library-only work, Joins, held some promise); and so on. Second, it didn’t help that everyone seemed to have a different idea on what the fundamental concepts should be.
But it really came down to isolation. Windows processes are too heavyweight for the fine-grained isolation we thought necessary to deliver safe, ubiquitous and easy message passing. And no sub-process isolation technology on Windows was really up for the task: COM apartments, CLR AppDomains, … many flawed attempts instantly come to mind; frankly, I did not want to die on that hill.
(Since then, I should note, there have been some nice efforts, like Orleans – built in part by some ex-Midori members – TPL Dataflow, and Akka.NET. If you want to do actors and/or message passing in .NET today, I recommend checking them out.)
Midori, on the other hand, embraced numerous levels of isolation, beginning with processes themselves, which were even cheaper than Windows threads thanks to software isolation. Even coarser-grained isolation was available in the form of domains, adding added belts-and-suspenders hardware protection for hosting untrusted or logically separate code. In the early days, we certainly wanted to go finer-grained too – inspired by E’s concept of “vats”, the abstraction we already began with for process message pumps – but weren’t sure how to do it safely. So we waited on this. But this gave us precisely what we needed for a robust, performant, and safe message passing foundation.
Important to the discussion of this architecture is the notion of shared nothing, something Midori leveraged as a core operating principle. Shared nothing architectures are great for reliability, eliminating single points of failure, however they are great for concurrency safety too. If you don’t share anything, there is no opportunity for race conditions! (This is a bit of a lie, and generally insufficient, as we shall see.)
It’s interesting to note that we were noodling on this around the same time Node.js was under development. The core idea of an asynchronous, non-blocking, single process-wide event loop, is remarkably similar. Perhaps something tasty was in the water during 2007-2009. In truth, many of these traits are common to event-loop concurrency.
This formed the canvas on top of which the entire concurrency model was painted. I’ve already discussed this in the asynchronous everything article. But there was more…
Why Not Stop Here?
It’s a reasonable question. A very robust system could be built with nothing more than the above, and I should say, throughout multiple years of pounding away at the system, the above foundation stood the test of time and underwent far fewer changes than what came next (syntax aside). There is a simplicity to leaving it at this that I admire. In fact, with perfect hindsight, I believe stopping here would have been a reasonable story for “V1.”
However, a number of things kept us pushing for more:
-
There was no sub-process parallelism. Notably absent were task and data parallelism. This was painful for a guy who had just come from building .NET’s task and PLINQ programming models. We had plenty of places that had latent parallelism just waiting to be unlocked, like image decoding, the multimedia pipeline, FRP rendering stack, browser, eventually speech recognition, and more. One of Midori’s top-level goals was to tackle the concurrency monster and, although a lot of parallelism came for “free” thanks to processes, the absence of task and data parallelism hurt.
-
All messages between processes required RPC data marshaling, so rich objects could not be shared. One solution to the absence of task parallelism could have been to model everything as processes. Need a task? Spawn a process. In Midori, they were cheap enough for this to work. Doing that, however, entailed marshaling data. Not only could that be an expensive operation, not all types were marshalable, severely limiting parallelizable operations.
-
In fact, an existing “exchange heap” was developed for buffers, loosely based on the concept of linearity. To avoid marshaling large buffers, we already had a system for exchanging them between processes without copying as part of the RPC protocol. This idea seemed useful enough to generalize and offer for higher-level data structures.
-
Even intra-process race conditions existed, due to multiple asynchronous activities in-flight and interleaving, despite the lack of data races thanks to the single message loop model described above. A benefit of the
awaitmodel is that interleaving are at least visible and auditable in the source code; but they could still trigger concurrency errors. We saw opportunities for the language and frameworks to help developers get this correct. -
Finally, we also had a vague desire to have more immutability in the system. Doing so could help with concurrency safety, of course, but we felt the language should also help developers get existing commonplace patterns correct-by-construction. We also saw performance optimization opportunities if the compiler could trust immutability.
We went back to academia and the ThinkWeek paper in search of inspiration. These approaches, if combined in a tasteful way, seemed like they could give us the tools necessary to deliver not only safe task and data parallelism, but also finer-grained isolation, immutability, and tools to possibly address some of the intra-process race conditions.
So, we forked the C# compiler, and went to town.
The Model
In this section, I will rearrange the story to be a bit out of order. (How appropriate.) I’ll first describe the system we ended up with, after many years of work, in “tutorial style” rather than starting with the slightly messier history of how we ended up there. I hope this gives a more concise appreciation of the system. I will then afterwards give the complete historical account, including the dozens of systems that came before which influenced us greatly.
We started with C#’s type system and added two key concepts: permission and ownership.
Permission
The first key concept was permission.
Any reference could have one and it governed what you could do with the referent object:
mutable: The target object (graph) can be mutated through the usual ways.readonly: The target object (graph) can be read from but cannot be mutated.immutable: The target object (graph) can be read from and will never be mutated.
A subtyping relationship meant you could implicitly convert either
mutableorimmutabletoreadonly. In other words,mutable <: readonlyandimmutable <: readonly.For example:
Foo m = new Foo(); // mutable by default. immutable Foo i = new Foo(); // cannot ever be mutated. i.Field++; // error: cannot mutate an immutable object. readonly Foo r1 = m; // ok; cannot be mutated by this reference. r1.Field++; // error: cannot mutate a readonly object. readonly Foo r2 = i; // ok; still cannot be mutated by this reference. r2.Field++; // error: cannot mutate a readonly object.These are guarantees, enforced by the compiler and subject to verification.
The default, if unstated, was
immutablefor primitive types likeint,string, etc., andmutablefor all others. This preserved existing C# semantics in almost all scenarios. (That is, C# compiled as-is had no change in meaning.) This was contentious but actually a pretty cool aspect of the system. It was contentious because the principle of least authority would lead you to choosereadonlyas the default. It was cool because you could take any C# code and start incrementally sprinkling in permissions where they delivered value. If we had decided to break from C# more radically – something in hindsight we should have done – then breaking with compatibility and choosing the safer default would have been the right choice; but given our stated goals of C# compatibility, I think we made the right call.These permissions could also appear on methods, to indicate how the
thisparameter got used:class List<T> { void Add(T e); int IndexOf(T e) readonly; T this[int i] { readonly get; set; } }A caller would need a sufficient permission in order to invoke a method:
readonly List<Foo> foos = ...; foos[0] = new Foo(); // error: cannot mutate a readonly object.A similar thing could be stated using delegate types and lambdas. For example:
delegate void PureFunc<T>() immutable;This meant that a lambda conforming to the
PureFuncinterface could only close overimmutablestate.Notice how powerful this has suddenly become! This
PureFuncis precisely what we would want for a parallel task. As we will see shortly, these simple concepts alone are enough to enable many of those PFX abstractions to become safe.By default, permissions are “deep”, in that they apply transitively, to the entire object graph. This interacts with generics in the obvious way, however, so that you could, for example, have combinations of deep and shallow permissions:
readonly List<Foo> foos = ...; // a readonly list of mutable Foos. readonly List<readonly Foo> foos = ...; // a readonly list of readonly Foos. immutable List<Foo> foos = ...; // an immutable list of mutable Foos. immutable List<immutable Foo> foos = ...; // an immutable list of immutable Foos. // and so on...Despite this working, and appearing obvious, man was this a difficult thing to get right!
For power users, we also had a way to write generic types that parameterized over permissions. This was definitely required deep in the bowels of highly generic code, but otherwise could be ignored by 90% of the system’s users:
delegate void PermFunc<T, U, V, permission P>(P T, P U, P V); // Used elsewhere; expands to `void(immutable Foo, immutable Bar, immutable Baz)`: PermFunc<Foo, Bar, Baz, immutable> func = ...;I should also note that, for convenience, you could mark a type as
immutableto indicate “all instances of this type are immutable.” This was actually one of the most popular features of all of this. At the end of the day, I’d estimate that 1/4-1/3 of all types in the system were marked as immutable:immutable class Foo {...} immutable struct Bar {...}There is an interesting twist. As we’ll see below,
readonlyused to be calledreadable, and was entirely distinct. But after we left Midori and were hard at work trying to ready these concepts for inclusion in C#, we decided to try and unify them. So that’s what I am presenting here. The only hitch is thatreadonlywould be given a slightly different meaning. On a field,readonlytoday means “the value cannot be changed”; in the case of a pointer, therefore, thereadonlyof today did not impact the referent object graph. In this new model, it would. Given that we anticipated an opt-in flag,--strict-mutability, this would be acceptable, and would requirereadonly mutable, a slight wart, to get the old behavior. This wasn’t a deal-breaker to me – especially given that a very common bug in C# is developers assuming thatreadonlyis deep (which now it would be), and obvious similarities toconstcome to mind.Ownership
The second key concept was ownership.
A reference could be given an ownership annotation, just as it could be given a permission:
isolated: The target object (graph) forms an unaliased transitive closure of state.
For example:
isolated List<int> builder = new List<int>();Unlike permissions, which indicate what operations are legal on a given reference, ownership annotations told us important aliasing properties about the given object graphs. An isolated graph has a single “in-reference” to the root object in the object graph, and no “out-references” (except for immutable object references, which are permitted).
A visual aid might help to conceptualize this:
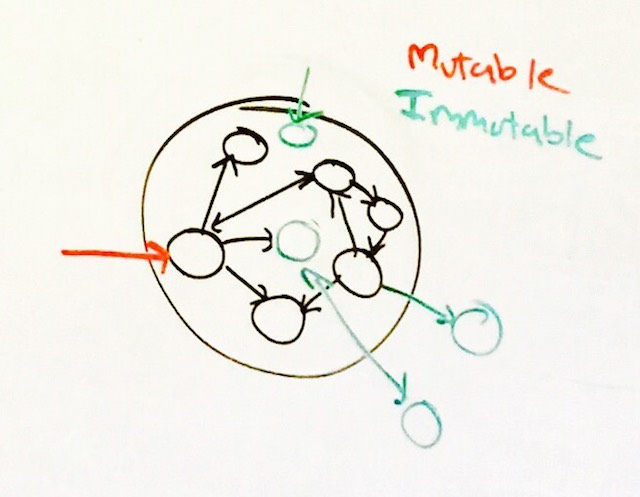
Given an isolated object, we can mutate it in-place:
for (int i = 0; i < 42; i++) { builder.Add(i); }And/or destroy the original reference and transfer ownership to a new one:
isolated List<int> builder2 = consume(builder);The compiler from here on would mark
builderas uninitialized, though if it is stored in the heap multiple possible aliases might lead to it, so this analysis could never be bulletproof. In such cases, the original reference would benulled out to avoid safety gotchas. (This was one of many examples of making compromises in order to integrate more naturally into the existing C# type system.)It’s also possible to destroy the isolated-ness, and just get back an ordinary
List<int>:List<int> built = consume(builder);This enabled a form of linearity that was useful for safe concurrency – so objects could be handed off safely, subsuming the special case of the exchange heap for buffers – and also enabled patterns like builders that laid the groundwork for strong immutability.
To see why this matters for immutability, notice that we skipped over exactly how an immutable object gets created. For it to be safe, the type system needs to prove that no other
mutablereference to that object (graph) exists at a given time, and will not exist forever. Thankfully that’s precisely whatisolatedcan do for us!immutable List<int> frozen = consume(builder);Or, more concisely, you’re apt to see things like:
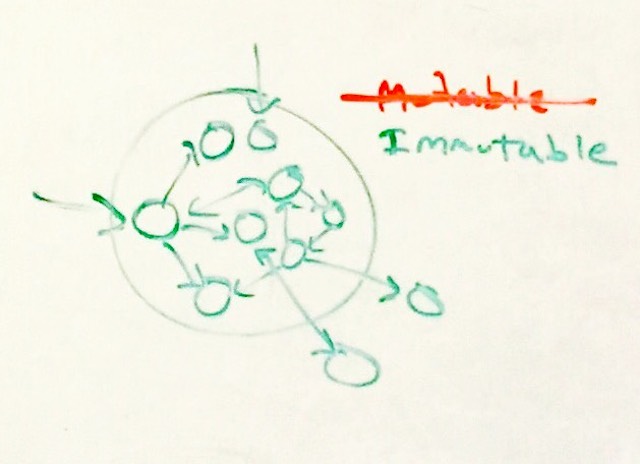
immutable List<int> frozen = new List<int>(new[] { 0, ..., 9 });In a sense, we have turned our isolation bubble (as shown earlier) entirely green:
Behind the scenes, the thing powering the type system here is
isolatedand ownership analysis. We will see more of the formalisms at work in a moment, however there is a simple view of this: all inputs to theList<int>’s constructor areisolated– namely, in this case, the array produced bynew[]– and therefore the resultingList<int>is too.In fact, any expression consuming only
isolatedand/orimmutableinputs and evaluating to areadonlytype was implicitly upgradeable toimmutable; and, a similar expression, evaluating to amutabletype, was upgradeable toisolated. This meant that making newisolatedandimmutablethings was straightforward using ordinary expressions.The safety of this also depends on the elimination of ambient authority and leaky construction.
No Ambient Authority
A principle in Midori was the elimination of ambient authority. This enabled capability-based security, however in a subtle way was also necessary for immutability and the safe concurrency abstractions that are to come.
To see why, let’s take our
PureFuncexample from earlier. This gives us a way to reason locally about the state captured by a lambda. In fact, a desired property was that functions accepting onlyimmutableinputs would result in referential transparency, unlocking a number of novel compiler optimizations and making it easier to reason about code.However, if mutable statics still exist, the invocation of that
PureFuncmay not actually be pure!For example:
static int x = 42; PureFunc<int> func = () => x++;From the type system’s point of view, this
PureFunchas captured no state, and so it obeys the immutable capture requirement. (It may be tempting to say that we can “see” thex++, and therefore can reject the lambda, however of course thisx++might happen buried deep down in a series of virtual calls, where it is invisible to us.)All side-effects need to be exposed to the type system. Over the years, we explored extra annotations to say “this function has mutable access to static variables”; however, the
mutablepermission is already our way of doing that, and felt more consistent with the overall stance on ambient authority that Midori took.As a result, we eliminated all ambient side-effectful operations, leveraging capability objects instead. This obviously covered I/O operations – all of which were asynchronous RPC in our system – but also even – somewhat radically – meant that even just getting the current time, or generating a random number, required a capability object. This let us model side-effects in a way the type-system could see, in addition to reaping the other benefits of capabilities.
This meant that all statics must be immutable. This essentially brought C#’s
constkeyword to all statics:const Map<string, int> lookupTable = new Map<string, int>(...);In C#,
constis limited to primitive constants, likeints,bools, andstrings. Our system expanded this same capability to arbitrary types, like lists, maps, …, anything really.Here’s where it gets interesting. Just like C#’s current notion of
const, our compiler evaluated all such objects at compile-time and froze them into the readonly segment of the resulting binary image. Thanks to the type system’s guarantee that immutability meant immutability, there was no risk of runtime failures as a result of doing so.Freezing had two fascinating performance consequences. First, we could share pages across multiple processes, cutting down on overall memory usage and TLB pressure. (For instance, lookup tables held in maps were automatically shared across all programs using that binary.) Second, we were able to eliminate all class constructor accesses, replacing them with constant offsets, leading to more than a 10% reduction in code size across the entire OS along with associated speed improvements, particularly at startup time.
Mutable statics sure are expensive!
No Leaky Construction
This brings us to the second “hole” that we need to patch up: leaky constructors.
A leaky constructor is any constructor that shares
thisbefore construction has finished. Even if it does so at the “very end” of its own constructor, due to inheritance and constructor chaining, this isn’t even guaranteed to be safe.So, why are leaky constructors dangerous? Mainly because they expose other parties to partially constructed objects. Not only are such objects’ invariants suspect, particularly in the face of construction failure, however they pose a risk to immutability too.
In our particular case, how are we to know that after creating a new supposedly-immutable object, someone isn’t secretively holding on to a mutable reference? In that case, tagging the object with
immutableis a type hole.We banned leaky constructors altogether. The secret? A special permission,
init, that meant the target object is undergoing initialization and does not obey the usual rules. For example, it meant fields weren’t yet guaranteed to be assigned to, non-nullability hadn’t yet been established, and that the reference could not convert to the so-called “top” permission,readonly. Any constructor got this permission by default and you couldn’t override it. We also automatically usedinitin select areas where it made the language work more seamlessly, like in object initializers.This had one unfortunate consequence: by default, you couldn’t invoke other instance methods from inside a constructor. (To be honest, this was actually a plus in my opinion, since it meant you couldn’t suffer from partially constructed objects, couldn’t accidentally invoke virtuals from a constructor, and so on.) In most cases, this was trivially worked around. However, for those cases where you really needed to call an instance method from a constructor, we let you mark methods as
initand they would take on that permission.Formalisms and Permission Lattices
Although the above makes intuitive sense, there was a formal type system behind the scenes.
Being central to the entire system, we partnered with MSR to prove the soundness of this approach, especially
isolated, and published the paper in OOPSLA’12 (also available as a free MSR tech report). Although the paper came out a couple years before this final model solidified, most of the critical ideas were taking shape and well underway by then.For a simple mental model, however, I always thought about things in terms of subtyping and substitution.
In fact, once modeled this way, most implications to the type system “fall out” naturally.
readonlywas the “top permission”, and bothmutableandimmutableconvert to it implicitly. The conversion toimmutablewas a delicate one, requiringisolatedstate, to guarantee that it obeyed the immutability requirements. From there, all of the usual implications follow, including substitution, variance, and their various impact to conversions, overrides, and subtypes.This formed a two-dimensional lattice wherein one dimension was “type” in the classical sense and the other “permission”, such that all types could convert to
readonly Object. This diagram illustrates: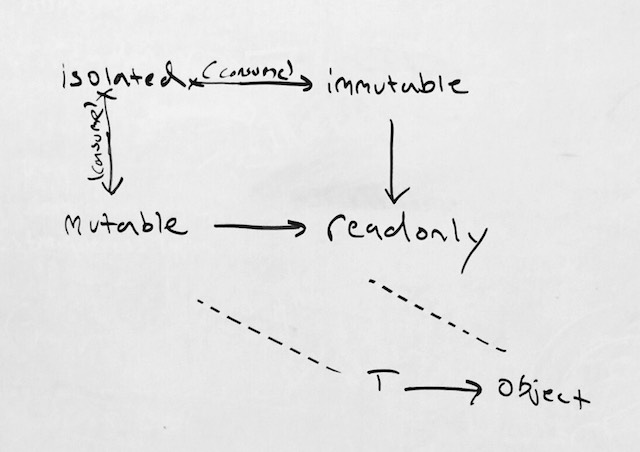
The system could obviously be used without any knowledge of these formalisms. However, I had lived through enough sufficiently scary, yet subtle, security problems over the years due to type system gotchas, so going the extra mile and doing the formalism not only helped us understand our own system better, but also helped us sleep better at night.
How This Enabled Safe Concurrency
New type system in hand, we can now go back and revisit those PFX abstractions, and make them all safe.
The essential property we must establish is that, when an activity has
mutablerights to a given object, then that object must not be simultaneously accessible to any other activities. Notice that I am using the term “activity” deliberately. For now, imagine this maps directly to “task”, although we shall return to this subtlety momentarily. Also note that I’ve said “object”; that too is a gross simplification, since for certain data structures like arrays, simply ensuring that activities do not havemutablerights to overlapping regions is sufficient.Beyond what this disallows, it actually allows for some interesting patterns. For instance, any number of concurrent activities may share
readonlyaccess to the same object. (This is a bit like a reader/writer lock, just without any locks or runtime overheads.) Remember that we can convertmutabletoreadonly, which means that, given an activity withmutableaccess, we can use fork/join parallelism that captures an object withreadonlypermissions, provided the mutator is temporally paused for the duration of this fork/join operation.Or, in code:
int[] arr = ...; int[] results = await Parallel.Fork( () => await arr.Reduce((x, y) => x+y), () => await arr.Reduce((x, y) => x*y) );This code computes the sum and product of an array, in parallel, by merely reading from it. It is data race-free.
How so? This example
ForkAPI uses permissions to enforce the required safety:public static async T[] Fork<T>(params ForkFunc<T>[] funcs); public async delegate T ForkFunc<T>() readonly;Let’s break this apart.
Forksimply takes an array ofForkFuncs. SinceForkisstatic, we needn’t worry about it capturing state dangerously. ButForkFuncis a delegate and can be satisfied by instance methods and lambdas, both of which can close over state. By marking thethisposition asreadonly, we limit the captures toreadonly; so, although the lambdas can capturearrin our above example, they cannot mutate it. And that’s it.Notice too that the nested function
Reducecan also be run in parallel, thanks toForkFunc! Obviously, all of the familiarParallel.For,Parallel.ForEach, and friends, can enjoy similar treatment, with similar safety.It turns out most fork/join patterns, where we can guarantee the mutator is paused, work this way. All of PLINQ, for example, can be represented this way, with complete data-race freedom. This was the use-case I always had in mind.
In fact, we can now introduce automatic parallelism! There are a few ways to go about this. One way is to never offer LINQ operators that aren’t protected by
readonlyannotations. This was always my preferred approach, given the absurdity of having query operators performing mutations. But other approaches were possible. One is to offer overloads – one set ofmutableoperators, one set ofreadonlyoperators – and the compiler’s overload resolution would then pick the one with the least permission that type-checked.As mentioned earlier, tasks are even simpler than this:
public static Task<T> Run<T>(PureFunc<T> func);This accepts our friend from earlier,
PureFunc, that is guaranteed to be referentially transparent. Since tasks do not have structured lifetime like our fork/join and data parallel friends above, we cannot permit capture of evenreadonlystate. Remember, the trick that made the above examples work is that the mutator was temporarily paused, something we cannot guarantee here with unstructured task parallelism.So, what if a task needs to party on mutable state?
For that, we have
isolated! There are various ways to encode this, however, we had a way to mark delegates to indicate they could captureisolatedstate too (which had the side-effect of making the delegate itselfisolated):public static Task<T> Run<T>(TaskFunc<T> func); public async delegate T TaskFunc<T>() immutable isolated;Now we can linearly hand off entire object graphs to a task, either permanently or temporarily:
isolated int[] data = ...; Task<int> t = Task.Run([consume data]() => { // in here, we own `data`. });Notice that we leveraged lambda capture lists to make linear captures of objects straightforward. There’s an active proposal to consider adding a feature like this to a future C#, however without many of the Midori features, it remains to be seen whether the feature stands on its own.
Because of the rules around
isolationproduction,mutableobjects produced by tasks could becomeisolated, andreadonlyobject could be frozen to becomeimmutable. This was tremendously powerful from a composition standpoint.Eventually, we created higher level frameworks to help with data partitioning, non-uniform data parallel access to array-like structures, and more. All of it free from data races, deadlocks, and the associated concurrency hazards.
Although we designed what running subsets of this on a GPU would look like, I would be lying through my teeth if I claimed we had it entirely figured out. All that I can say is understanding the side-effects and ownership of memory are very important concepts when programming GPUs, and we had hoped the above building blocks would help create a more elegant and unified programming model.
The final major programming model enhancement this enabled was fine-grained “actors”, a sort of mini-process inside of a process. I mentioned the vat concept earlier, but that we didn’t know how to make it safe. Finally we had found the missing clue: a vat was really just an
isolatedbubble of state. Now that we had this concept in the type system, we could permit “marshaling” ofimmutableandisolatedobjects as part of the message passing protocol without marshaling of any sort – they could be shared safely by-reference!I would say that the major weakness of this system was also its major benefit. The sheer permutations of concepts could be overwhelming. Most of them composed nicely, however the poor developers creating the underlying “safe concurrency” abstractions – myself included – almost lost our sanity in doing so. There is probably some generics-like unification between permissions and ownership that could help here, however the “funniness” of linearity is hard to quarantine.
Amazingly, it all worked! All those cases I mentioned earlier – image decoders, the multimedia stack, the browser, etc. – could now use safe intra-process parallelism in addition to being constructed out of many parallel processes. Even more interestingly, our one production workload – taking Speech Recognition traffic for Bing.com – actually saw significant reductions in latency and improvements in throughput as a result. In fact, Cortana’s DNN-based speech recognition algorithms, which delivered a considerable boost to accuracy, could have never reached their latency targets were it not for this overall parallelism model.
Sequential Consistency and Tear-Free Code
There was another unanticipated consequence of safe concurrency that I quite liked: sequential consistency (SC).
For free.
After all those years trying to achieve a sane memory model, and ultimately realizing that most of the popular techniques were fundamentally flawed, we had cracked the nut. All developers got SC without the price of barriers everywhere. Given that we had been running on ARM processors where a barrier cost you 160 cycles, this gave us not only a usability edge, but also a performance one. This also gave our optimizing compiler much more leeway on code motion, because it could now freely order what used to be possibly-side- effectful operations visible to multiple threads.
To see how we got SC for free, consider how the overall system was layered.
At the bottom of all of the above safe concurrency abstractions, there was indeed
unsafecode. This code was responsible for obeying the semantic contract of safe concurrency by decorating APIs with the right permissions and ownership, even if the implementation physically violated them. But it is important to note: this is the only code in the system – plus the 1st party kernel code – that had to deal with concurrency at the threads, locks, events, and lock-free level of abstraction. Everything else built atop the higher-level abstractions, where barriers had already been placed into the instruction stream at all the right places, thanks to the infrastructure.This had another consequence: no struct tearing was visible in the 3rd party programming model. Everything was “atomic”, again for free.
This allowed us to use multi-word slice and interface representations, just like Go does, but without the type-safety- threatening races. It turns out, the risk of struct tearing is one of major factors preventing us from having a great Go-like slice type to C# and .NET. In Midori, slices were safe, efficient, and everywhere.
Message Passing Races
Message passing helps tremendously when building correct, reliable concurrent systems, however it is not a panacea. I had mentioned shared nothing earlier on. It’s a dirty little secret, however, even if you don’t have shared memory, but agents can communicate with one another, you still have shared state encoded in the messaging between those agents, and the opportunity for race conditions due to the generally unpredictable order of arrival of these messages.
This is understood, although perhaps not very widely. The most worrisome outcome from these kind of races is time of check time of use (TOCTOU), one of the more common kinds of races that can lead to security vulnerabilities. (Midori’s type- and memory-safety of course helps to avoid this particular symptom, however reliability problems are very real also.)
Although people used to hate it when I compared this situation to COM STAs, for those familiar with them, an analogy is apt. If you need to block a thread inside of a COM STA, you must decide: Do I pump the message loop, or do I not pump the message loop? If you choose to pump the message loop, you can suffer reentrancy, and that reentrancy might be witness to broken invariants, or even mutate state out from underneath the blocking call, much to its dismay after it reawakens. If you choose not to pump the message loop, you can suffer deadlock, as calls pile up, possibly ones that are required to unblock the thread.
In Midori’s system, we did not give this choice to the developer. Instead, every
awaitwas an opportunity to pump the underlying message loop. Just as with a COM STA, these pumps possibly dispatched work that might interact with shared state. Note that this is not parallelism, mind you, since process event loops did not permit parallelism, however there is possibly a lot of concurrency going on here, and it can definitely screw you:async bool IsRed(AsyncColor c) { return (await c.R > 0 && await c.G == 0 && await c.B == 0); }This rather simple (and silly) function checks to see if an
AsyncColoris “red”; to do so, it reads theR,G, andBproperties. For whatever reason, they are asynchronous, so we mustawaitbetween accesses. IfAsyncColoris a mutable object, well, guess what – these values might change after we’ve read them, opening up a possible TOCTOU bug. For instance, imagine a caller’s surprise whenIsRedmay have lied to it:AsyncColor c = ...; await IsRed(c); assert(await c.R > 0);That assertion can very well fire. Even this callsite has a TOCTOU bug of its own, since
c.Rmight be>0at the end ofIsRed’s return, but not after theassertexpression’s ownawaithas completed.All of this should be familiar territory for concurrency experts. But we sought to eliminate these headaches.
This area of the system was still under active development towards the end of our project, however we had sketched out a very promising approach. It was to essentially apply similar permission annotations to asynchronous activity – hence my choice of the term “activity” earlier – as we did parallel tasks. Although this seriously limited an asynchronous activity’s state purview, combined with a reader/writer-lock like idea, meant that we could use permissions affixed to asynchronous interfaces to automatically ensure state and asynchronous operations were dispatched safely.
Evolution
Before moving on, a brief word on the evolution of the system. As I mentioned earlier, I presented the system in its final form. In reality, we went through five major phases of evolution. I won’t bore you with exhaustive details on each one, although I will note the major mistakes and lessons learned in each phase.
In the first phase, I tried to build the system entirely out of annotations that were “outside” of the type system. As I’ve already said, that failed spectacularly. At this point, I hope you can appreciate how deeply integrated into the compiler and its type system these concepts need to be for them to work and for the result to be usable.
Next, I tried a variant of this with just
readonly. Except I called itreadable(a name that would stick until the very tail end of the project), and it was always deep. There was noimmutableand there was noisolated. The concept ofmutablewas calledwritable, although I was delusional, and thought you’d never need to state it. I was very confused about the role generics played here, and ended up coding myself up into a corner trying to make it work.After that, I recognized at least that
readableandwritablewere related to one another, and recognized the subtyping relationship of (writable <: readable). And, largely based on conversations with colleagues in MSR, I decided to toss out everything I had done on generics and redo it. It was at that time I recognized that each generic type variable, despite looking like a naked type, actually carried both a permission and a type. That helped.I then came up with
immutable, however it wasn’t what you see today. Instead, it had the slightly confusing meaning of being a “view” over just the immutable subset of data in the target object graph. (This was at first limited to onlyreadonlyfields (in the classical C# sense) that were of a primitive type.) If you tried reading a non-immutable part from this view, you’d get a compiler error. Bizarrely, this meant you could have animmutable List<T>that wasn’t actually immutable. In hindsight, this was pretty wonky, but it got us thinking about and discussing immutability.Somewhere in here, we recognized the need for generic parameterization over permissions, and so we added that. Unfortunately, I originally picked the
%character to indicate that a generic type was a permission, which was quite odd; e.g.,G<%P>versusG<T>. We renamed this topermission; e.g.,G<permission P>versusG<T>.There was one problem. Generic permissions were needed in way more places than we expected, like most property getters. We experimented with various “shortcuts” in an attempt to avoid developers needing to know about generic permissions. This hatched the
readable+annotation, which was a shortcut for “flow thethisparameter’s permission.” This concept never really left the system, although (as we will see shortly), we fixed generics and eventually this concept became much easier to swallow, syntax-wise (especially with smart defaults like auto-properties).We lived with this system for some time and this was the first version deployed at-scale into Midori.
And then a huge breakthrough happened: we discovered the concepts necessary for
isolatedand, as a result, animmutableannotation that truly meant that an object (graph) was immutable.I can’t claim credit for this one. That was the beauty of getting to this stage: after developing and prototyping the initial ideas, and then deploying them at-scale, we suddenly had our best and brightest obsessing over the design of this thing, because it was right under their noses. This was getting an initial idea out in front of “customers” early-and-often at its finest, and, despite some growing pains, worked precisely as designed.
We then wallowed in the system for another year and 1/2 and, frankly, I think lost our way a little bit. It turns out deepness was a great default, but sometimes wasn’t what you wanted.
List<T>is a perfect example; sometimes you want theListto bereadonlybut the elements to bemutable. In the above examples, we took this capability for granted, but it wasn’t always the case. The outerreadonlywould infect the innerTs.Our initial whack at this was to come up with shallow variants of all the permissions. This yielded keywords that became a never-ending source of jokes in our hallways:
shreadable,shimmutable, and – our favorite –shisolated(which sounds like a German swear word when said aloud). Our original justification for such nonsense was that in C#, the signed and unsigned versions of some types used abbreviations (sbyte,uint, etc.), andshallowsure would make them quite lengthy, so we were therefore justified in our shortening into ashprefix. How wrong we were.From there, we ditched the special permissions and recognized that objects had “layers”, and that outer and inner layers might have differing permissions. This was the right idea, but like most ideas of this nature, we let the system get inordinately more complex, before recognizing the inner beauty and collapsing it back down to its essence.
At the tail end of our project, we were working to integrate our ideas back into C# and .NET proper. That’s when I was adamant that we unify the concept of
readablewithreadonly, leading to several keyword renames. Ironically, despite me having left .NET to pursue this project several years earlier, I was the most optimistic out of anybody that this could be done tastefully. Sadly, it turned out I was wrong, and the project barely got off the ground before getting axed, however the introductory overview above is my best approximation of what it would have looked like.Inspirations
Now that we have seen the system in its final state, let’s now trace the roots back to those systems that were particularly inspiring for us. In a picture:
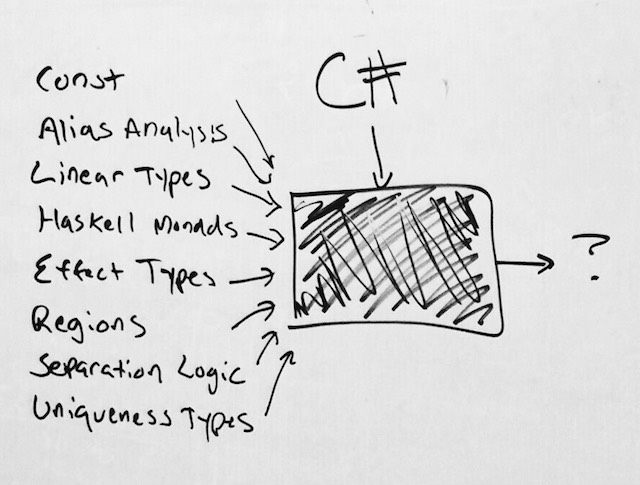
I’ll have to be brief here, since there is so much ground to cover, although there will be many pointers to follow up papers should you want to dive deeper. In fact, I read something like 5-10 papers per week throughout the years I was working on all of this stuff, as evidenced by the gigantic tower of papers still sitting in my office:

const
The similarities with
constshould, by now, be quite evident. Although people generally have a love/hate relationship with it, I’ve always found that beingconstcorrect is worth the effort for anything bigger than a hobby project. (I know plenty of people who would disagree with me.)That said,
constis best known for its unsoundness, thanks to the pervasive use ofconst_cast. This is commonly used at the seams of libraries with different views onconstcorrectness, although it’s also often used to cheat; this is often for laziness, but also due to some compositional short-comings. The lack of parameterization overconst, for example, forces one to duplicate code; faced with that, many developers would rather just cast it away.constis also not deep in the same way that our permissions were, which was required to enable the safe concurrency, isolation, and immutability patterns which motivated the system. Although many of the same robustness benefits thatconstcorrectness delivers were brought about by our permissions system, that wasn’t its original primary motivation.Alias Analysis
Although it’s used more as a compiler analysis technique than it is in type systems, alias analysis is obviously a close cousin to all the work we did here. Although the relationship is distant, we looked closely at many uses of aliasing annotations in C(++) code, including
__declspec(noalias)in Visual C++ andrestrict(__restrict,__restrict__, etc.) in GCC and standard C. In fact, some of our ideas aroundisolatedeventually assisted the compiler in performing better alias analysis.Linear Types
Phillip Wadler’s 1990 “Linear types can change the world!” was immensely influential for me in the early days. I remember a huge lightbulb going off when I first read this paper. Linear types are inspired by the linear logic of J.-Y. Girard, and it is easy to get lost in the mathematics for hours.
In a nutshell, a linear type lets you prove that a variable is used exactly once. This is similar to
isolated, however due to the aliasing properties of an imperative language like C# (especially for heap structures with possible cycles between them), the simple and elegant model of strict linearity is hard to make work.Linear types themselves also aren’t very commonly seen in the wild, and are mostly useful for their mathematical and proof properties. If you go looking, you will find examples, however. More than real syntax in real languages, linear types have been hugely influential on subsequent innovations in type systems that also impacted us, such as affine and uniqueness types.
Haskell Monads
In the early days, I was pretty obsessed with Haskell, to put it mildly.
I often describe the above system that we built as the inverse of the Haskell state monad. In Haskell, what you had was a purely functional language, with sugar to make certain aspects look imperative. If you wanted side-effects, you needed to enter the beautiful world of monads. In particular, for simple memory side-effects, the state monad let you have traditional mutable data structures, but in a way that the type system very much understood and could restrict for safety where appropriate.
Well, the system we built was sort of the opposite: you were in an imperative language, and had a way of marking certain aspects of the program as being purely functional. I am pretty sure I read the classic “State in Haskell” paper at least a dozen times over the years. In fact, as soon as I recognized the similarities, I compared notes with Simon Peyton-Jones, who was immensely gracious and helpful in working through some very difficult type system design challenges.
Effect Types
Effect typing, primarily in the ML community, was also influential in the early days. An effect type propagates information at compile-time describing the dynamic effect(s) executing said code is expected to bring about. This can be useful for checking many properties.
For example, I always thought of
awaitandthrowsannotations as special kinds of effects that indicate a method might block or throw an exception, respectively. Thanks to the additive and subtractive nature of effect types, they propagate naturally, and are even amenable to parametric polymorphism.It turns out that permissions can be seen as a kind of effect, particularly when annotating an instance method. In a sense, a
mutableinstance method, when invoked, has the “effect” of mutating the receiving object. This realization was instrumental in pushing me towards leveraging subtyping for modeling the relationship between permissions.Related to this, the various ownership systems over the years were also top-of-mind, particularly given Midori’s heritage with Singularity, which used the Spec# language. This language featured ownership annotations.
Regions
Regions, despite classically being used mostly for deterministic and efficient memory management, were incredibly interesting towards the days of figuring out
isolated.They aren’t identical for several reasons, however.
The first reason is that isolated object graphs in our system weren’t as strictly partitioned as regions, due to immutable in- and out- references. Regions are traditionally used to collect memory efficiently and hence dangling references like this wouldn’t be permitted (and the reachability analysis to detect them would basically devolve into garbage collection).
The second reason is that we wanted to avoid the syntactic burden of having regions in the language. A good example of this in action is Deterministic Parallel Java, which requires explicit region annotations on objects using a very generics-like syntax (e.g.,
Foo<region R>). Some amount of this can be hidden from the developer through more sophisticated compiler analysis – much like Cyclone did – however, we worried that in some very common cases, regions would rear their ugly heads and then the developer would be left confused and dismayed.All that said, given our challenges with garbage collection, in addition to our sub-process actor model, we often pondered whether some beautiful unification of
isolatedobject graphs and regions awaited our discovery.Separation Logic
Particularly in the search for formalisms to prove the soundness of the system we built, separation logic turned out to be instrumental, especially the concurrent form. This is a formal technique for proving the disjointness of different parts of the heap, which is very much what our system is doing with the safe concurrency abstractions built atop the
isolatedprimitive. In particular, our OOPSLA paper used a novel proof technique, Views, which can be constructed from separation algebras. Caution: this is getting into some very deep mathematical territory; several colleagues far smarter than I am were the go-to guys on all of this. But, it certainly helped all of us sleep better at night.Uniqueness Types
Uniqueness types are a more recent invention, derived from some of the early linear type systems which so fascinated me early on. For a period of time, we actually had a
uniquekeyword in the language. Eventually we folded that back into the concept ofisolated(it was essentially a “shallow”isolated). But there is no denying that all of this was heavily inspired by what we saw with uniqueness types, especially in languages like Clean, the experimental work to bring uniqueness to Scala, and, now, Rust.Model Checking
Finally, I would be remiss if I didn’t at least mention model checking. It’s easy to confuse this with static analysis, however, model checking is far more powerful and complete, in that it goes beyond heuristics and therefore statistics. MSR’s Zing and, although we used it to verify the correctness of certain aspects of our implementation, I don’t think we sufficiently considered how model checking might impact the way safety was attained. This was top-of-mind as we faced intra-process interleaving race conditions. Especially as we look to the future with more distributed-style concurrency than intra-process parallelism, where state machine verification is critical, many key ideas in here are relevant.
Other Languages
This story spans many years. During those years, we saw several other languages tackling similar challenges, sometimes in similar ways. Because of the complex timeline, it’s hard to trace every single influence to a given point in time, however it’s fair to say that four specific languages had a noteworthy influence on us.
(Note that there are dozens of influential concurrent and parallel languages that inspired our work. I’m sure I haven’t read everything there is to read – there’s always more to learn – however I did my best to survey the field. I will focus here on the most mainstream and relevant to people writing production code in the year 2016.)
(Modern) C++
I already mentioned
constand its influence.It is also interesting to note the similarities between
isolatedand C++11’sstd::unique_ptr. Although born in different times, and in very different worlds, they both clearly deliver a similar perspective on ownership. Noted difference include deepness – C++’s approach is “deep” insofar as you leverage RAII faithfully in your data structures – and motivations – C++’s motivation being primarily memory management, and neither safe concurrency nor immutability.The concept of
constexprhas obvious similarities to bothisolatedandimmutable, particularly the compile-time evaluation and freezing of the results. The continued evolution ofconstexprin C++13 and C++17 is taking the basic building blocks to new frontiers that I had always wanted to do with our system, but never had time, like arbitrary compile-time evaluation of expressions, and freezing/memoization of the results.Thankfully, because I was leading the C++ group at Microsoft for some time after Midori, I was able to bring many of our lessons learned to the discussion, and I like to think it has had a positive impact on evolving C++ even further.
D
The system we came up with has obvious comparisons to D’s take on
constandimmutable; just as D’sconstis a view over mutable or immutable data, so too is ourreadonly. And just as D added deepness to the concept ofconst, so did we in our permissions model generally. This is perhaps the closest analogy in any existing systems. I am frankly surprised it doesn’t get used an order of magnitude more than it does, although Andrei, one of its chief developers, has some thoughts on that topic.Go
Although I personally love programming in Go, it didn’t have as much influence on our system as you might expect. Go lists concurrency as one of its primary features. Although concurrency is easy to generate thanks to
goroutines, and best practices encourage wonderful things like “Share Memory by Communicating”, the basic set of primitives doesn’t go much beyond the threads, thread-pools, locks, and events that I mention us beginning with in the early days of this journey.On one hand, I see that Go has brought its usual approach to bear here; namely, eschewing needless complexity, and exposing just the bare essentials. I compare this to the system we built, with its handful of keywords and associated concept count, and admire the simplicity of Go’s approach. It even has nice built-in deadlock detection. And yet, on the other hand, when I find myself debugging classical data races, and torn structs or interfaces, I clamor for more. I have remarked before that simply running with
GOMAXPROCS=1, coupled with a simple RPC system – ideally integrated in such a way where you needn’t step outside of Go’s native type system – can get you close to the simple “no intra-process parallelism” Midori model that we began with. And perhaps the best sweet spot of all.Rust
Out of the bunch, Rust has impressed me the most. They have delivered on much of what we set out to deliver with Midori, but actually shipped it (whereas we did not). My hat goes off to that team, seriously, because I know first hand what hard, hard, hard work this level of type system hacking is.
I haven’t yet described our “borrowed references” system, or the idea of auto-destructible types, however when you add those into the mix, the underlying type system concepts are remarkably similar. Rust is slightly less opinionated on the overall architecture of your system than Midori was, which means it is easier to adopt piecemeal, however the application of these concepts to traditional concurrency mechanisms like locks is actually fascinating to see.
This article gives a great whirlwind tour of safe concurrency in Rust. Poking through to some of the references reveals APIs designed with similar principles in mind. For example,
simple_parallellooks a whole lot like the PFXParallelAPI described earlier with safety annotations applied to it. I trust their system more than ours, because they have shipped and had thousands of eyes and real-world experience applied to it.Epilogue and Conclusion
Although I’ve glossed over many details, I hope you enjoyed the journey, and that the basic ideas were clear. And, most importantly, that you learned something new. If you want to understand anything in greater detail, please see our OOPSLA paper, or just ask.
It’s been a couple years since I’ve been away from this. As most of you know, Midori happened before the OSS renaissance at Microsoft, and so it never saw the light of day. In that time, I’ve pondered what lessons we learned on this journey, and whether any of it is relevant beyond the hallways of our old building 34. I believe it is, otherwise I’d not have taken the time to write up this article.
I’m thrilled that the world has adopted tasks in a big way, although it was for a different reason than we expected (asynchrony and not parallelism). In many ways this was inevitable, however I have to think that doing tasks a half-decade ahead of the curve at least had a minor influence, including the
asyncandawaitideas built atop it.Data parallelism has taken off…sort of. Far fewer people leverage CPUs in the way we imagined, but that’s for good reason: GPUs are architected for extremely wide SIMD operations over floating points, which is essentially the killer scenario for this sort of parallelism. It doesn’t cover all of the cases, but man does it scream.
Safe concurrency is still critically important, yet lacking, and the world still needs it. I think we collectively underestimated how long it would take for the industry to move to type- and memory-safe programming models. Despite the increasing popularity of safe systems languages like Go and Rust, it pains me to say it, but I still believe we are a decade away from our fundamental technology stacks – like the operating systems themselves – being safe to the core. But our industry desperately needs this to happen, given that buffer errors remain the #1 attack type for critical security vulnerabilities in our software.
I do think that concurrency-safety will be our next frontier after type- and memory-safety have arrived. TOCTOU, and race conditions generally, are an underexploited yet readily attackable vector. (Thankfully, just as writing correct concurrent code is hard, so too is provoking a latent concurrency error through the delicate orchestration of race conditions). As more systems become concurrent (distributed) systems this will become an increasing problem for us. It’s not clear the exact formulation of techniques I demonstrated above is the answer – in fact, given our focus on parallelism over asynchrony, surely it is not – however we will need some answer. It’s just too damn hard to build robust, secure, and safe concurrent programs, still, to this day, 15 years later.
In particular, I’m still conflicted about whether all those type system extensions were warranted. Certainly immutability helped with things far beyond safe concurrency. And so did the side-effect annotations, as they commonly helped to root out bugs caused by unintended side-effects. The future for our industry is a massively distributed one, however, where you want simple individual components composed into a larger fabric. In this world, individual nodes are less “precious”, and arguably the correctness of the overall orchestration will become far more important. I do think this points to a more Go-like approach, with a focus on the RPC mechanisms connecting disparate pieces.
The model of leveraging decades of prior research was fascinating and I’m so happy we took this approach. I literally tried not to invent anything new. I used to joke that our job was to sift through decades of research and attempt to combine them in new and novel ways. Although it sounds less glamorous, the reality is that this is how a lot of our industry’s innovation takes place; very seldom does it happen by inventing new ideas out of thin air.
Anyway, there you have it. Next up in the series, we will talk about Battling the GC.